







Announcing the Annotation for Transparent Inquiry (ATI) Initiative
We are excited to announce the first round of published projects from our Annotation for Transparent Inquiry (ATI) Initiative. ATI creates a digital overlay on top of articles generated through qualitative and multi-method research published on journal web pages. That overlay connects specific passages of text to author-generated annotations.
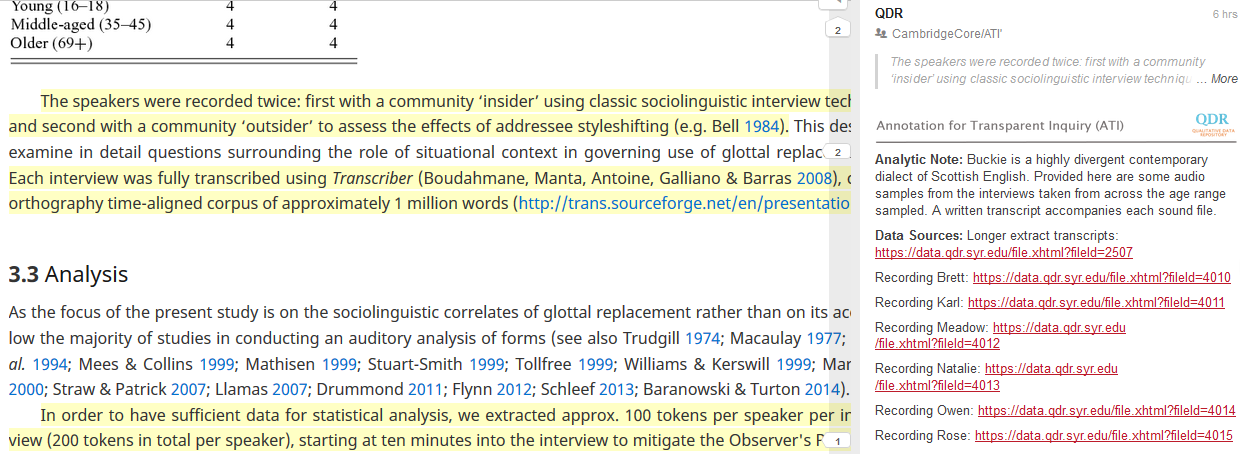
ATI’s annotations include ‘analytic notes’ discussing data generation and analysis, excerpts from data sources, and links to those sources stored in trusted digital repositories. Readers are able to view annotations immediately alongside the main text, removing the need to jump to footnotes or separate appendices. Sharing the data sources via a secure repository ensures that they are findable, accessible, interoperable, reusable, and preserved for the long term, and that human participants are protected.
In a partnership with Cambridge University Press and Hypothesis (the non-profit tech company on whose software ATI is built), and with generous funding from the Robert Wood Johnson Foundation (RWJF) and the National Science Foundation, QDR assembled an interdisciplinary group of scholars to annotate a journal article that each had recently published.
Participating scholars were drawn from diverse disciplines including anthropology, linguistics, political science, and public health. The annotated articles are published in some of the leading journals in these disciplines, including the American Political Science Review, International Organization, English Language & Linguistics and the Journal of Biosocial Science.

In a workshop this February, the authors met with a group of reviewers--as well as representatives from QDR, Hypothesis, Cambridge University Press, and RWJF--to discuss their ATI data projects and the future of ATI. Cambridge University Press has generously agreed to make all participating papers freely available until March 2019. We encourage you to browse through all of these projects.
| Article Citation | ATI Link |
|---|---|
| Arrey, Agnes Ebotabe, Johan Bilsen, Patrick Lacor, and Reginald Deschepper. 2017. “Perceptions of Stigma and Discrimination in Health Care Settings towards Sub-Saharan African Migrant Women Living with Hiv/Aids in Belgium: A Qualitative Study.” Journal of Biosocial Science 49 (5): 578–96. https://doi.org/10.1017/S0021932016000468 | Click here |
| Gans-Morse, Jordan. 2017. “Demand for Law and the Security of Property Rights: The Case of Post-Soviet Russia.” American Political Science Review 111 (2): 338–59. https://doi.org/10.1017/S0003055416000691. | Click here |
| Moorlock, Greg, James Neuberger, Simon Bramhall, and Heather Draper. 2016. “An Empirically Informed Analysis of the Ethical Issues Surrounding Split Liver Transplantation in the United Kingdom.” Cambridge Quarterly of Healthcare Ethics 25 (3): 435–47. https://doi.org/10.1017/S0963180116000086 | Click here |
| O’Mahoney, Joseph. 2017. “Making the Real: Rhetorical Adduction and the Bangladesh Liberation War.” International Organization 71 (2): 317–48. https://doi.org/10.1017/S0020818317000054 | Click here |
| Pierskalla, Jan, Alexander De Juan, and Max Montgomery. 2017. “The Territorial Expansion of the Colonial State: Evidence from German East Africa 1890–1909.” British Journal of Political Science, FirstView, 1–27. https://doi.org/10.1017/S0007123416000648 | Click here |
| Skarbek, David. 2016. “Covenants without the Sword? Comparing Prison Self-Governance Globally.” American Political Science Review 110 (4): 845–62. https://doi.org/10.1017/S0003055416000563 | Click here |
| Smith, Jennifer, and Sophie Holmes-Elliott. 2017. “The Unstoppable Glottal: Tracking Rapid Change in an Iconic British Variable.” English Language & Linguistics, January, 1–33. https://doi.org/10.1017/S1360674316000459 | Click here |
| Tidy, Joanna. 2017. “Visual Regimes and the Politics of War Experience: Rewriting War ‘from above’ in WikiLeaks’ ‘Collateral Murder.’” Review of International Studies 43 (1): 95–111. https://doi.org/10.1017/S0260210516000164 | Click here |
ATI projects connected to eight articles published in journals from other publishers were also discussed at the workshop, and will be made available in the near future.
As part of the ATI Initiative, we also solicited feedback from all participating authors and formal evaluations by the reviewers. Our goal is to understand where and how ATI can be employed most fruitfully, and how we can support researchers’ workflows to ease the additional workload of generating ATI annotations. We expect to present the insights we gained about ATI through the workshop and the generous input of participating scholars later this year.
ATI Challenge
We are now inviting faculty and advanced graduate students in the social and health sciences, humanities, law, and other disciplines that employ qualitative data and methods, to submit proposals to participate in the ATI Challenge.
ATI Challenge participants will receive an award of $2,000 (as either an honorarium or research support), subject to any relevant tax and visa status limitations. They will also attend a workshop in New York City in November 2018, where they will meet and network with other scholars who share a commitment to making their research accessible and evaluable. All travel and accommodation expenses will be covered by QDR.
The proposal deadline is May 31, 2018 (extended from the original May 11 deadline). Additional information can be found here. Please contact QDR (qdr@syr.edu) with questions.